Structure of nucleic acids
Nucleotides are the building blocks of nucleic acids, such as DNA and RNA
Each nucleotide is composed of three main components: a sugar molecule (ribose or deoxyribose), a nitrogenous base, and a phosphate group.
The sugar molecule forms the backbone of the nucleic acid, while the nitrogenous base provides genetic information.
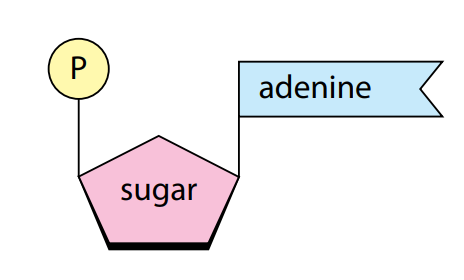
There are five types of nitrogenous bases: adenine (A), guanine (G), cytosine (C), thymine (T), and uracil (U).
The purines, adenine and guanine, have a double ring structure, while the pyrimidines, cytosine, thymine, and uracil, have a single ring structure.
The phosphate group is a critical component of nucleotides as it helps to link the nucleotides together to form a long chain, known as a nucleic acid.
The phosphorylated nucleotide ATP (adenosine triphosphate) is particularly important as it acts as a source of energy in cells.
ATP consists of an adenine molecule, a ribose sugar molecule, and three phosphate groups linked together by high-energy bonds. These high-energy bonds can be broken to release energy, making ATP an important source of energy for cellular processes.
Structure of DNA
DNA is made up of four nitrogenous bases: adenine (A), guanine (G), cytosine (C), and thymine (T).
The nitrogenous bases in each strand of the DNA molecule are paired through hydrogen bonds, forming base pairs. The complementary base pairing between the two strands is essential for the stability and function of DNA.
In DNA, adenine pairs with thymine (A-T) and guanine pairs with cytosine (C-G). The pairing of nitrogenous bases creates a stable structure and helps maintain the integrity of the genetic information stored in the DNA molecule.
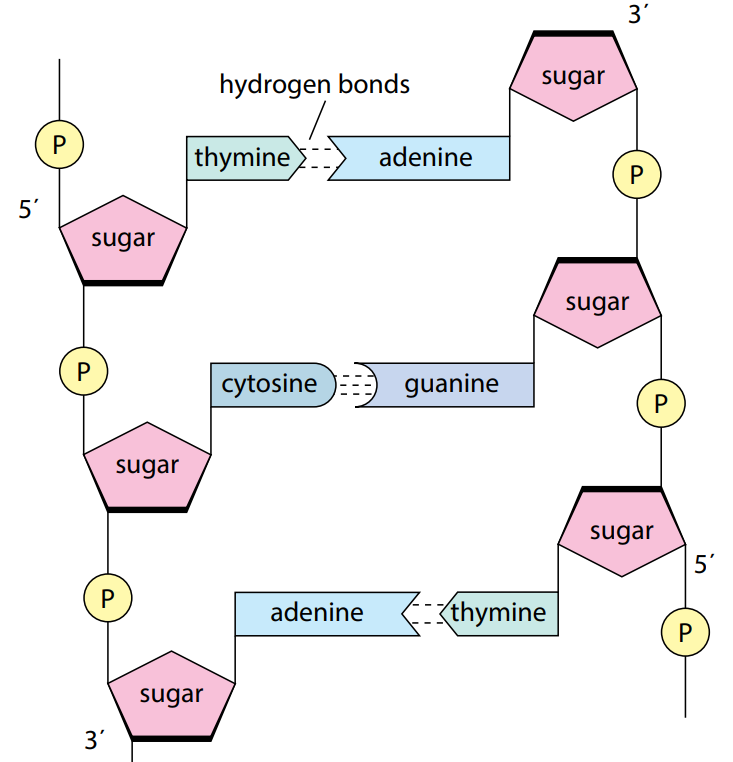
The hydrogen bonds between the nitrogenous bases are not equally strong. The hydrogen bonds between C-G base pairs are stronger than those between A-T base pairs.
The double helix structure of DNA is maintained by the formation of phosphodiester bonds between nucleotides. In this process, the phosphate group of one nucleotide is linked to the hydroxyl group of the next nucleotide in the chain, forming a sugar-phosphate backbone.
The two strands of the DNA double helix run in opposite directions, with one strand running from the 5′ end to the 3′ end and the other running from the 3′ end to the 5′ end.
The structure of the DNA molecule is essential for the proper functioning of DNA. The stability and the complementary base pairing make it possible for DNA to be replicated and passed on from one generation to the next, ensuring the preservation of genetic information.
DNA replication
DNA replication is the process by which a cell makes an exact copy of its genetic material, the DNA, before cell division.
During the S phase of the cell cycle, DNA replication occurs in a semi-conservative manner, meaning that each new strand of DNA contains one original strand and one new strand.
The process of DNA replication begins with the unwinding of the double helix structure and the separation of the complementary strands by DNA helicase.
This exposes the nitrogenous bases, which are held together by hydrogen bonds, to be used as a template for the synthesis of new complementary strands.
DNA polymerase is responsible for adding nucleotides to the new strand. It moves along the template strand in a 5′ to 3′ direction, adding nucleotides that complement the nitrogenous bases in the template strand. The new strand is constructed in the 5′ to 3′ direction as well, making it complementary to the template strand.
DNA replication is said to occur in a semi-conservative manner because the two complementary strands separate, and each serves as a template for the synthesis of a new complementary strand.
There are two ways in which DNA replication can occur: leading strand replication and lagging strand replication.
In leading strand replication, DNA polymerase adds nucleotides continuously to the new strand, resulting in a continuous replication of the template strand.
On the other hand, lagging strand replication is discontinuous, as the new strand is constructed in segments, called Okazaki fragments, which are later joined together by the action of DNA ligase.
mRNA
RNA is a single-stranded molecule that is similar in structure to DNA but is made up of different nitrogenous bases.
RNA is synthesized from DNA through a process called transcription and acts as a template for the synthesis of proteins.
Messenger RNA (mRNA) is a type of RNA that carries genetic information from the DNA in the nucleus to the ribosome in the cytoplasm, where it acts as a template for protein synthesis.
The structure of mRNA is characterized by a nitrogenous base (adenine, guanine, cytosine, and uracil), a sugar molecule (ribose), and a phosphate group.
The nitrogenous bases in mRNA are linked by glycosidic bonds between the sugar molecule and the phosphate group, forming a chain-like structure.
The nitrogenous bases in mRNA determine the sequence of amino acids in the protein being synthesized.
Protein synthesis
Proteins are made up of polypeptides, which are chains of amino acids. The sequence of amino acids in a polypeptide is determined by the genetic information stored in a gene.
The genetic code is a set of rules that describe how sequences of DNA bases (nucleotides) correspond to sequences of amino acids in a polypeptide. The genetic code is universal, meaning that it is the same for all organisms.
Transcription and translation are the two key processes of protein synthesis.
Transcription:
Transcription is the process of synthesizing messenger RNA (mRNA) from DNA. It is catalyzed by the enzyme RNA polymerase.
RNA polymerase recognizes the start of a gene in the DNA strand and separates the two DNA strands by breaking the hydrogen bonds holding the two strands together.
The strand of a DNA molecule that is used in transcription is called the transcribed or template strand and that the other strand is called the non-transcribed strand.
Breaking allows RNA polymerase access to the DNA template strand.
RNA polymerase then moves along the DNA template strand and synthesizes a complementary RNA molecule.
The RNA polymerase adds nucleotides to the RNA molecule, matching the base pairing rule (A-U, C-G), and covalently bonds the ribonucleotides together by forming phosphodiester bonds between the nucleotides.
RNA polymerase continues to add nucleotides to the growing RNA molecule until it reaches a stop codon, which signals the end of the gene.
At this point, RNA polymerase releases the RNA molecule and the hydrogen bonds holding the two DNA strands together re-form, allowing the DNA to return to its double-stranded state.
Translation
Translation is the process by which the genetic information stored in a messenger RNA (mRNA) molecule is used to synthesize a protein. The process of translation occurs on ribosomes, which are cellular structures composed of protein and RNA.
The following steps describe the process of translation:
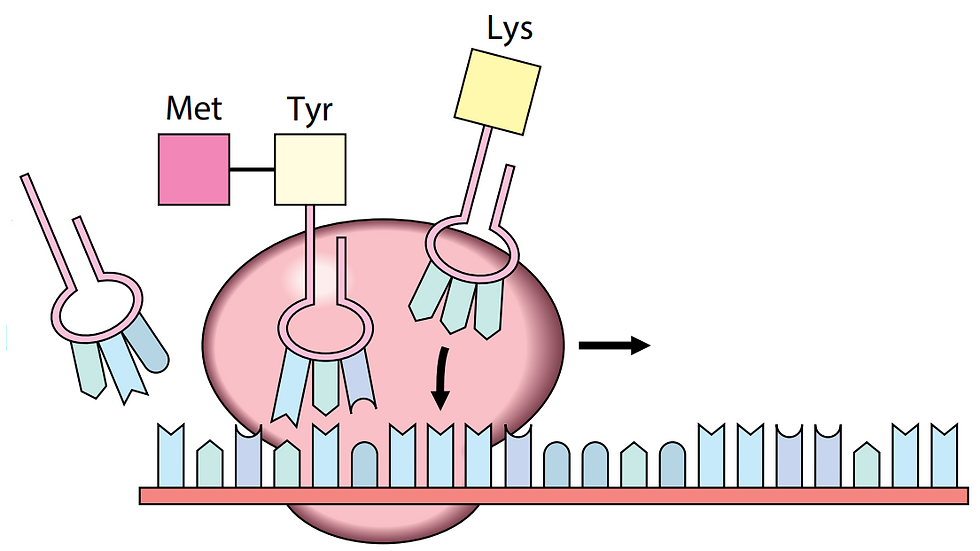
The ribosome recognizes the start codon (usually AUG) on the mRNA molecule and binds to it, positioning itself at the start of the coding sequence. The ribosome then recruits an initiator tRNA molecule carrying the amino acid methionine.

2. The ribosome moves along the mRNA molecule, adding amino acids to the growing polypeptide chain. This occurs by adding tRNA molecules carrying the appropriate amino acids to the ribosome, with each tRNA molecule recognized by the ribosome through its anticodon, which is complementary to the codon on the mRNA.

3. The ribosome catalyzes the formation of a peptide bond between the carboxyl group of one amino acid and the amino group of the next, linking the amino acids into a polypeptide chain.
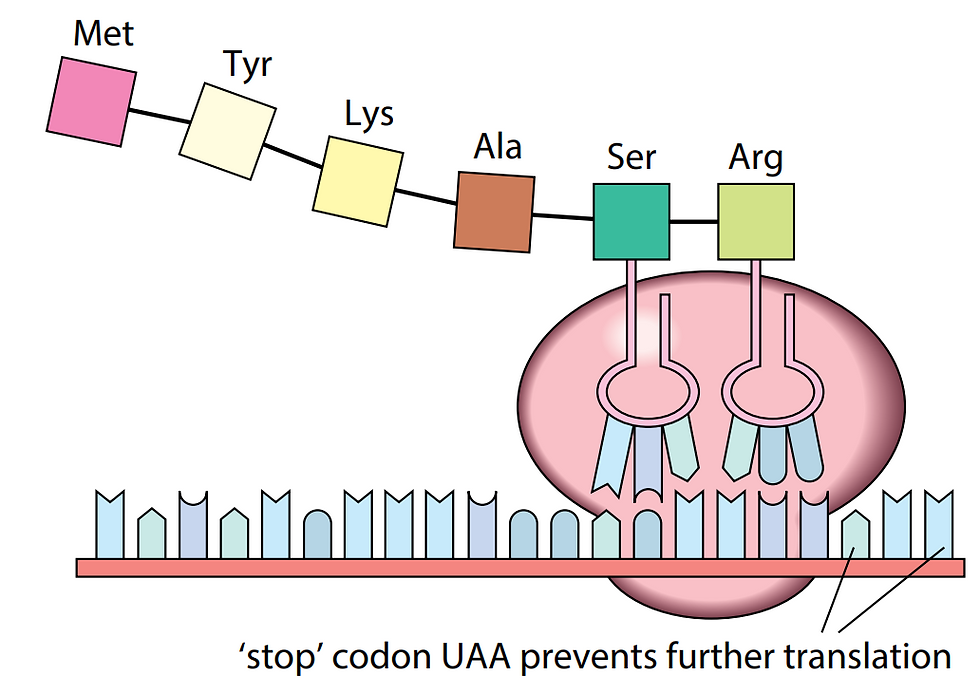
4. The ribosome reaches a stop codon (UAA, UAG, or UGA) on the mRNA molecule, and the ribosome is released from the mRNA. The completed polypeptide is then folded into its final three-dimensional structure and becomes functional.
Splicing
In eukaryotes, the RNA molecule formed following transcription is known as the primary transcript.
The primary transcript typically contains both coding (exons) and non-coding (introns) sequences.
Before the primary transcript can be used as a template for protein synthesis, it undergoes a process called splicing.
Splicing removes the introns and joins the exons together to form the mature mRNA molecule.
This process allows for greater diversity in the expression of genes through alternative splicing, producing multiple different protein products from the same gene.
Splicing is crucial in the expression of genes in eukaryotes by forming the mature mRNA molecule, which can then be used as a template for protein synthesis.
Gene mutations
A gene mutation is a change in the sequence of base pairs in a DNA molecule, which can result in an altered polypeptide. Mutations can occur through:
Substitution mutations: Involve the replacement of one nucleotide with another. This can result in a change in the amino acid produced by a particular codon, leading to a different polypeptide being produced. For example, a single nucleotide change in the DNA sequence can result in a different amino acid being coded, potentially leading to changes in the structure and function of the protein.
Deletion mutations: Involve the loss of one or more nucleotides from the DNA sequence. This can result in a frameshift in the coding sequence, altering the subsequent amino acids produced and changing the entire polypeptide produced.
Insertion mutations: Involve the addition of one or more nucleotides to the DNA sequence. Like deletions, this can result in a frameshift in the coding sequence, altering the subsequent amino acids produced and changing the entire polypeptide produced.
Nonsense mutations: Involve a change in the DNA sequence that results in a premature stop codon, causing the protein synthesis to halt before its full length is achieved. This can result in a truncated, non-functional protein.
Comments